Values to use for simulation should be defined for covariates used in the statistical model, if the simulation is based on population parameters. In this case, new individual parameters are simulated from the population distributions and the covariate values. Several covariate elements can be defined in Definition, but only one covariate element should be used per simulation group in Simulation. No covariate element can be used in Exploration, since only individual parameters are used in Exploration.
Demo projects: 3.2. covariates
New covariate element
Several types of covariate elements can be defined:
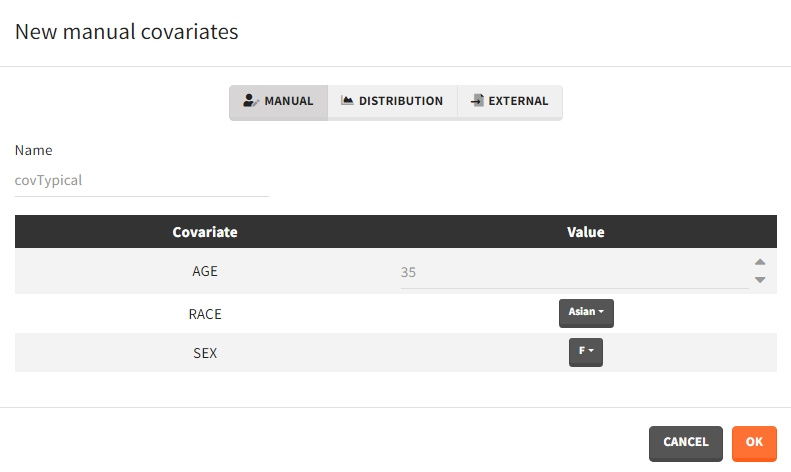
- Manual: It is a vector that has one or several dosing times with identical or different amounts. The + and – buttons allow to add and remove doses.
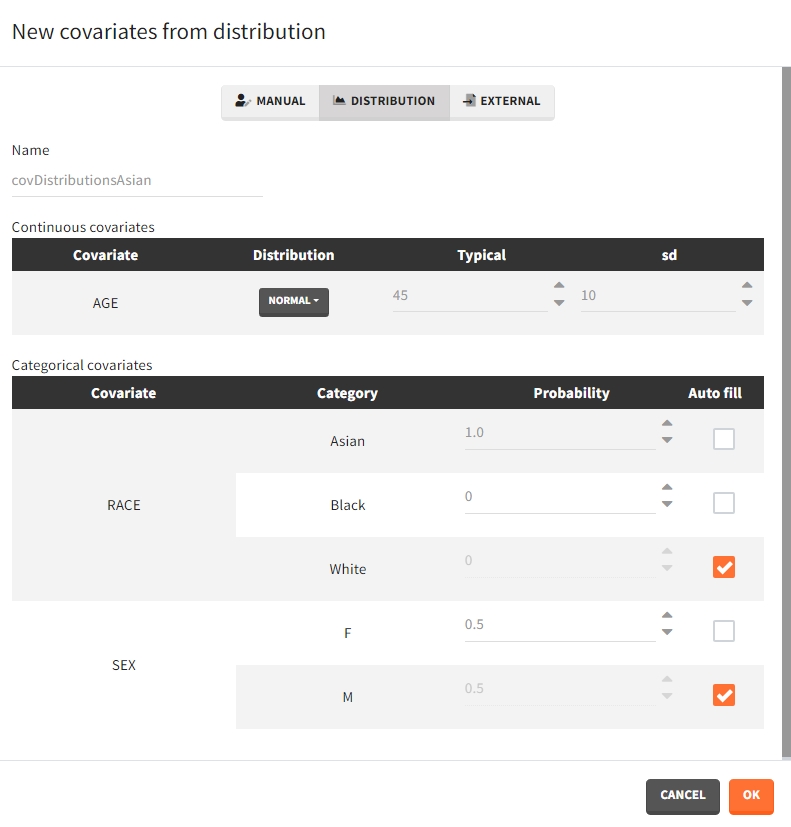
- Distribution: The covariates are described with distribution laws. When this type of element is used for simulation, new covariate values are simuated from the distributions. For continuous covariates, the distribution can be normal, lognormal or logitnormal with a mean and sd, or uniform with two interval limits. If the distribution is lognormal or logitnormal, sd is the standard deviation of the distribution in the Gaussian space. The typical value is the median of the covariate distribution..
 In the case of a lognormal distribution, in order to get the sd \(s_G\) of the distribution in the Gaussian space given a typical value of the lognormally distributed covariate \(\mu\), or given its mean \(m\), and given its sd \(s\), you can use the following formulas:
In the case of a lognormal distribution, in order to get the sd \(s_G\) of the distribution in the Gaussian space given a typical value of the lognormally distributed covariate \(\mu\), or given its mean \(m\), and given its sd \(s\), you can use the following formulas:
\[s_G = \sqrt{\ln\Big(1+\Big(\frac{s}{m}\Big)^2\Big)} = \sqrt{\ln\Bigg(1+\sqrt{1+4\Big(\frac{s}{\mu}\Big)^2}\Bigg) – \ln(2)}\]
Both formulas are equivalent if \(\frac{s}{\mu}<<1\) (in that case \(\mu \approx m\)).
For categorical covariates, the probability for each category can be defined in [0,1]. The sum of probabilities over all categories must be 1, and an “auto fill” option allows to automatically fill one or several of the categories to satisfy this rule.
- External: An external text file with columns id (optional), occasions (optional), and one column per covariate (mandatory). The occasions headers must correspond to the occasion names defined in the occasion element. When id and occasion columns are present, then they must be the first columns. When the id column is not present, the covariate is considered ‘common’, i.e the same for all individuals. Categorical covariate values must correspond to the categories defined in the model (block [COVARIATE]).The external file can be tab, comma or semicolon separated. The possible file extensions are .csv or .txt.
Covariate elements imported from Monolix
Importing a Monolix project generates automatically a covariate element based on the Monolix data set.
- mlx_Cov: contains covariate information for each individual. The table is saved as external table in the result folder of the project. This table contains a column id, and one column per covariate. If there are occasions in the Monolix project, it also contains one or several columns for the occasion levels.
- mlx_CovDist: element of type “distribution” with typical values, standard deviations and probabilities calculated on the individuals of the Monolix project. No correlation between the covariates is assumed. In the 2020 version, all continuous covariates are assumed to follow a normal distribution. In the 2021 version, continuous covariates having only strictly positive values in the Monolix data set are assumed to follow a log-normal distribution, and the others are set with a normal distribution.
